
Fig. 1. A representative sequence of 32 points from the training set at the onset of chaos.
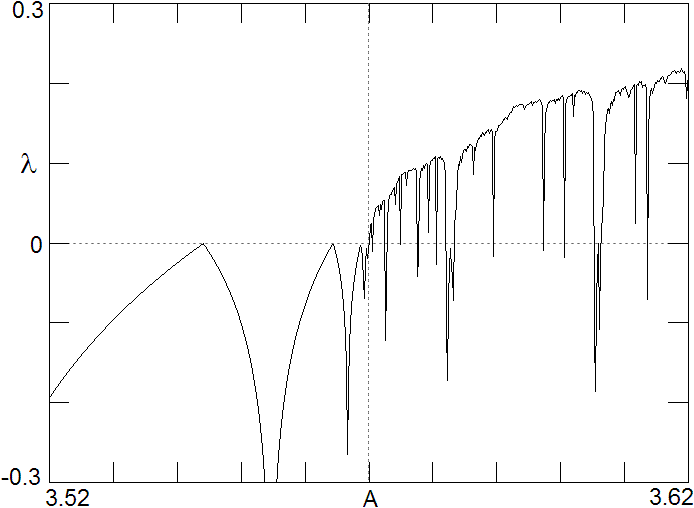
Fig. 2. Lyapunov exponent as a function of A for the logistic map, showing the accumulation point at A = 3.4699456718... where chaos onsets.

Fig. 3. Three typical instances of the training showing how the error e decreases with training trial.
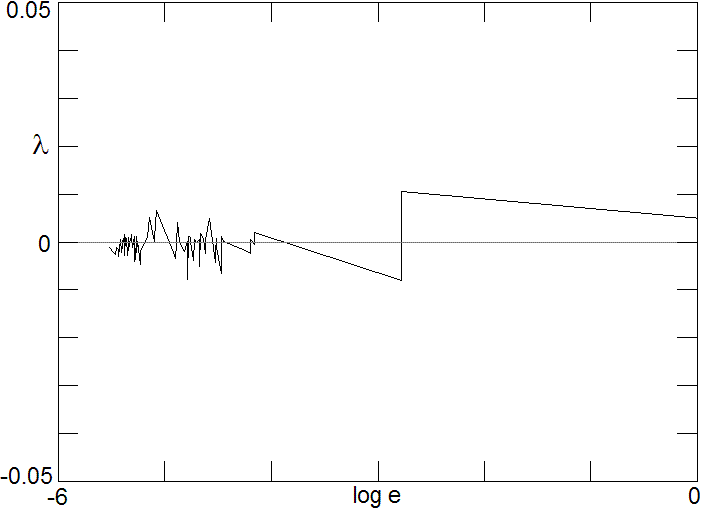
Fig. 4. Typical variation of the Lyapunov exponent during one instance of the training as the error decreases, showing how positive and negative regions are visited.
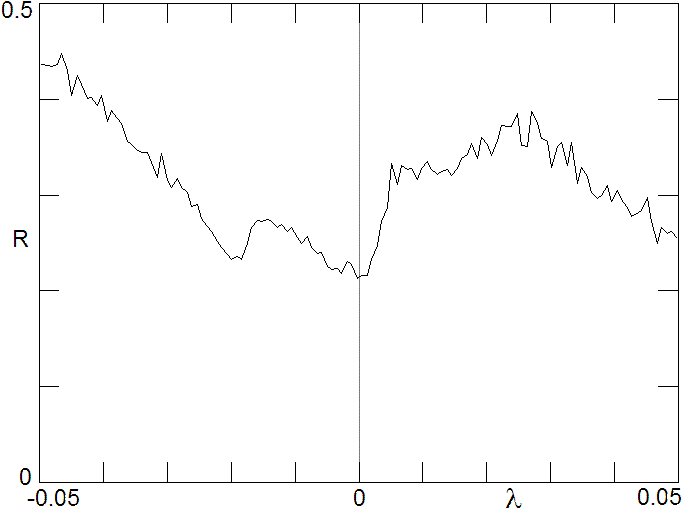
Fig. 5. Average learning rate as a function of Lyapunov exponent in the vicinity of the solution at lambda = 0 showing that weak chaos (positive lambda) is beneficial for learning in this artificial network.